Privacidade de bate-papo de IA em risco: Microsoft detalha ataque de canal lateral Whisper Leak
A Microsoft descobriu o Whisper Leak, um ataque de canal lateral que permite que bisbilhoteiros de rede inferam tópicos de bate-papo de IA, apesar da criptografia, arriscando a privacidade do usuário.
Microsoft revelou Um novo ataque de canal lateral Chamado Vazamento de sussurro, que permite que os invasores que podem monitorar o tráfego de rede infiram o que os usuários discutem com modelos de linguagem remotos, mesmo quando os dados são criptografados. A empresa alertou que essa falha pode expor detalhes confidenciais de conversas de usuários ou empresas com sistemas de IA de streaming, criando sérios riscos à privacidade.
Os chatbots de IA agora desempenham papéis importantes na vida cotidiana e em áreas sensíveis, como saúde e direito. Proteger os dados do usuário com fortes políticas de anonimização, criptografia e retenção é vital para manter a confiança e a privacidade.
Os chatbots de IA usam HTTPS (TLS) para criptografar as comunicações, garantindo conexões seguras e autenticadas. Os modelos de linguagem geram token de texto por token, saídas de streaming para feedback mais rápido. O TLS usa criptografia assimétrica para trocar chaves simétricas por cifras como AES ou ChaCha20, que mantêm o tamanho do texto cifrado próximo ao tamanho do texto simples. Estudos recentes revelam riscos de canal lateral em modelos de IA: os invasores podem inferir padrões de comprimento, tempo ou cache do token para adivinhar tópicos de prompt. O Whisper Leak da Microsoft expande isso, mostrando como os padrões de tráfego criptografados por si só podem revelar temas de conversa.
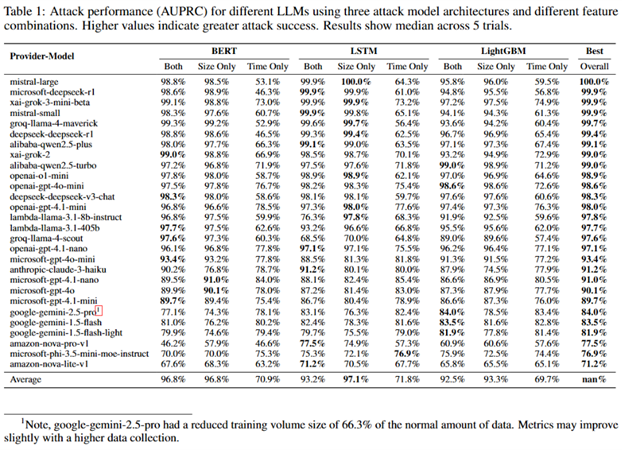
Os pesquisadores da Microsoft treinaram um classificador binário para detectar quando um bate-papo com um modelo de linguagem envolvia um tópico específico, “legalidade da lavagem de dinheiro”, versus tráfego geral. Eles geraram 100 prompts relacionados a tópicos e mais de 11.000 não relacionados, capturando tempos de resposta e tamanhos de pacotes via tcpdump enquanto randomizavam amostras para evitar viés de cache. Usando LightGBM,Bi-LSTMeBERT modelos, eles testaram tempo, tamanho e dados combinados. Muitos modelos alcançaram mais de 98% de precisão (AUPRC), provando que os padrões de rede específicos do tópico deixam “impressões digitais” digitais identificáveis.
“Avaliamos o desempenho usando a Área Sob a Curva de Precisão-Recall (AUPRC), que é uma medida do sucesso de um ataque cibernético para conjuntos de dados desequilibrados (muitas amostras negativas, menos amostras positivas).” lê o relatório publicado pela Microsoft. “Uma rápida olhada na coluna “Melhor geral” mostra que, para muitos modelos, o ataque cibernético alcançou pontuações acima de 98%. Isso nos diz que as “impressões digitais” digitais exclusivas deixadas por conversas sobre um tópico específico são distintas o suficiente para que nosso bisbilhoteiro com inteligência artificial as identifique de forma confiável em um teste controlado.
Uma simulação de um cenário de vigilância realista descobriu que, mesmo ao monitorar 10.000 conversas aleatórias com apenas uma sobre um tópico sensível, os invasores ainda podiam identificar alvos com precisão alarmante. Muitos modelos de IA testados permitiram 100% de precisão, todas as conversas sinalizadas correspondiam corretamente ao tópico, enquanto detectavam de 5 a 50% de todas as conversas de destino. Isso significa que invasores ou agências podem identificar com segurança usuários discutindo questões confidenciais, apesar da criptografia. Embora as projeções sejam limitadas pelos dados de teste, os resultados indicam um risco real e crescente à medida que os invasores coletam mais dados e refinam os modelos.
“Em testes estendidos com um modelo testado, observamos uma melhoria contínua na precisão do ataque à medida que o tamanho do conjunto de dados aumentava.” continua o relatório. “Combinado com modelos de ataque mais sofisticados e os padrões mais ricos disponíveis em conversas de vários turnos ou várias conversas do mesmo usuário, isso significa que um invasor cibernético com paciência e recursos pode alcançar taxas de sucesso mais altas do que nossos resultados iniciais sugerem.”
A Microsoft compartilhou suas descobertas com OpenAI, Mistral, Microsoft e xAI, que implementaram mitigações para reduzir o risco identificado.
OpenAI e, posteriormente, Microsoft Azure, adicionaram um Obscurecimento campo para respostas de streaming, inserindo texto aleatório para mascarar comprimentos de token e reduzir drasticamente a eficácia do ataque; o teste confirma que a correção do Azure reduz o risco a níveis não práticos. O Mistral introduziu uma mitigação semelhante por meio de um novo parâmetro “p”.
Embora seja principalmente um problema de provedor de IA, os usuários podem aumentar a privacidade evitando tópicos confidenciais em redes não confiáveis, usando VPNs, escolhendo provedores com mitigações, optando por modelos sem streaming e mantendo-se informados sobre as práticas de segurança.
Siga-me no Twitter:@securityaffairseLinkedineMastodonte
(Assuntos de Segurança–hacking,Whisper Leak)